
人工智能(AI)潜在的应用与日俱增。不同的神经网络(NN)经过测试、调整和改进,解决了不同的问题。出现了使用AI优化数据分析的各种方法。今天大部分的AI应用,比如谷歌翻译和亚马逊Alexa语音识别和视觉识别系统,还在利用云的力量。通过依赖一直在线的互联网连接,高带宽链接和网络服务,物联网产品和智能手机应用也可以集成AI功能。到目前为止,大部分注意力都集中在基于视觉的人工智能上,一部分原因是它容易出现在新闻报道和视频中,另一部分原因是它更类似于人类的活动。

声音和视觉神经网络(图片来源于:CEVA)
在图像识别中,对一个2D图像进行分析(一次处理一组像素),通过神经网络的连续层识别更大的特征点。最开始检测到的边缘是具有高差异性的部位。以人脸为例,最早识别的边缘是在眼睛、鼻子和嘴巴这些特征周边。随着检测过程在神经网络中的深入,将会检测到整个面部的特征。
在最后阶段,结合特征和位置信息,就能在可用的数据库中识别到具有最大匹配度的一个特定的人脸。

神经网络的特征提取(图片来源于:CEVA)
相机拍摄或捕捉的物体,可以通过神经网络在其数据库找到具有最高匹配概率的人脸。尤其好的是物体不需要在完全相同的角度或位置,或者是相同的光线条件下进行拍摄。
AI这么快就流行起来,在很大程度上是因为开放的软件工具(也称为框架),使得构建和训练一个神经网络实现目标应用程序变得容易起来,即使是使用各种不同的编程语言。两个常见的通用框架是TensorFlow和Caffe。对于已知的识别目标,可以离线定义和训练一个神经网络。一旦训练完成,神经网络可以很容易地部署到嵌入式平台上。这是一个聪明的划分,允许借助PC或云的能力训练神经网络,而功耗敏感的嵌入式处理器只需使用训练好的数据来进行识别。
类人的识别人和物体的能力与流行的应用密切相关,比如工业机器人和自动驾驶汽车。
然而,人工智能在音频领域具备同样的兴趣点和能力。采用和图像特征分析同样的方式,可以将音频分解成特征点来输入给神经网络。有一种方法是使用梅尔频率倒谱系数(MFCC)将音频分解成有用的特征。最开始音频样本被分解成短时间的帧,例如20 ms,然后对信号进行傅里叶变换,使用重叠三角窗将音频频谱的功率映射到一个非线性尺度上。
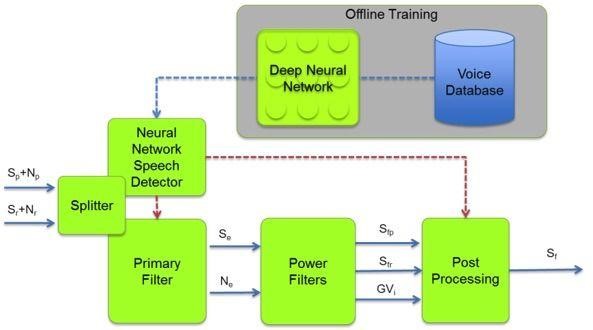
声音神经网络分解图(图片来源于:CEVA)
通过提取的特征,神经网络可以用来确定音频样本和音频样本数据库中词汇或者语音的相似度。和图像识别一样,神经网络为特定词汇在数据库中提取了可能的匹配。对于那些想要复制谷歌和亚马逊的“OK Google”或“Alexa”语音触发(VT)功能的人来说,KITT.AI通过Snowboy提供了一个解决方案。触发关键词可以上传到他们的平台进行分析,导出一个文件,集成到嵌入式平台上的Snowboy应用程序中,这样语音触发(VT)的关键词在离线情况下也可以被检测到。音频识别也并不局限于语言识别。TensorFlow提供了一个iOS上的示例工程,可以区分男性和女性的声音。
另一个应用程序是检测我们居住的城市和住宅周围动物和其它声音。这已经由安装在英国伊丽莎白女王奥林匹克公园的深度学习蝙蝠监控系统验证过了。它提供了将视觉和听觉识别神经网络集成到一个平台的可能性。比如通过音频识别特定的声音,可以用来触发安全系统进行录像。
有很多基于云的AI应用程序是不现实的,一方面有数据隐私问题,另一方面由于数据连通性差或带宽不够造成的服务不能持续。另外,实时性能也是一个值得关注的问题。例如工业制造系统需求一个瞬时响应,以实时操作生产线,连接云服务的延时就太长了。
因此,将AI功能移动到终端设备越来越受到关注。也就是说,在正在使用的设备上发挥人工智能的力量。很多IP供应商提供了解决方案,比如CEVA的CEVA-X2和NeuPro IP核和配套软件,很容易和现有的神经网络框架进行集成。它为开发具备人工智能的嵌入式系统提供了可能性,同时提供了低功耗处理器的灵活性。以一个语音识别系统作为例子,可以利用集成在芯片上的功耗优化的人工智能,来识别一个语音触发(VT)的关键词和一个最小的语音命令(VC)的集合。更复杂的语音命令和功能,可以在应用程序从低功耗的语音触发状态下唤醒之后,由基于云的AI完成。
最后,卷积神经网络(CNN)也可以用来提高文本到语音(TTS)系统的质量。一直以来TTS是将来自同一个配音员的许多小块的高质量录音,整合成连续的声音。虽然所输出的结果是人类可以理解的,但由于输出结果存在奇怪的语调和音调,仍然感觉像是机器人的声音。如果试图表现不同的情绪则需要一组全新的录音。谷歌的WaveNet改善了当前的情况,通过卷积神经网络(CNN)以每秒16000个采样生成TTS波形。与之前的声音样本相比,其输出结果是无缝连接的,明显更自然更高质量的声音。
本文主要内容引自 eepw
513 thoughts on “嵌入式神经网络赋予机器视觉、听觉和分析能力”