
站在2018年,图像分类准确率在95%以上的模型,已经遍地都是。
回想2012年,Hinton带着学生们以ImageNet上16.4%的错误率震惊计算机视觉研究界,似乎已经是远古时期的历史。
这些年来的突飞猛进,真的可信吗?
最近一项研究引出了一些反思:这些进步很可疑。
这项研究,就是加州大学伯克利分校和MIT的几名科学家在arXiv上公开的一篇论文:Do CIFAR-10 Classifiers Generalize to CIFAR-10?。
解释一下,这个看似诡异的问题——“CIFAR-10分类器能否泛化到CIFAR-10?”,针对的是当今深度学习研究的一个大缺陷:
看起来成绩不错的深度学习模型,在现实世界中不见得管用。因为很多模型和训练方法取得的好成绩,都来自对于那些著名基准验证集的过拟合。
论文指出,过去5年间,大多数发表的论文拥抱了这样一种范式:一种新的机器学习方法在几个关键基准测试中数据,就决定了它的地位。
然而,这种方法与前人相比,为什么会有这样的进步?却很少有人解释。我们对于进步的感知主要基于几个标准的基准测试,比如CIFAR-10、ImageNet、MuJoCo。
这就带来了一个关键的问题:我们目前对机器学习进步的衡量方法,有多可靠?
这个指控,几乎要质疑图像分类算法几年来的一切进步。
空口无凭,如何证明?
为了说明这个问题,几位作者拿出30个在CIFAR-10验证集上表现良好的图像分类模型,换一个数据集来测试它们,用结果说话。
CIFAR-10包含60000张32×32像素的彩色图像,平均分为5个训练批次(batch)和1个测试批次图像共有10类:飞机、小汽车、鸟、猫、鹿、狗、青蛙、……

当然,如果随便找个数据集来测试,有欺负AI的嫌疑。他们为此专门造了一个和CIFAR-10非常相似的测试集,包含2000张新图片,一样的图片来源,一样的数据子类别分布,甚至连构建过程中的分工都学了过来。
这个新数据集,也就是论文标题中提到的第二个CIFAR-10,确切地说应该是“高仿CIFAR-10的小型测试集”。
新测试集给模型带来了明显的打击,战况如下:
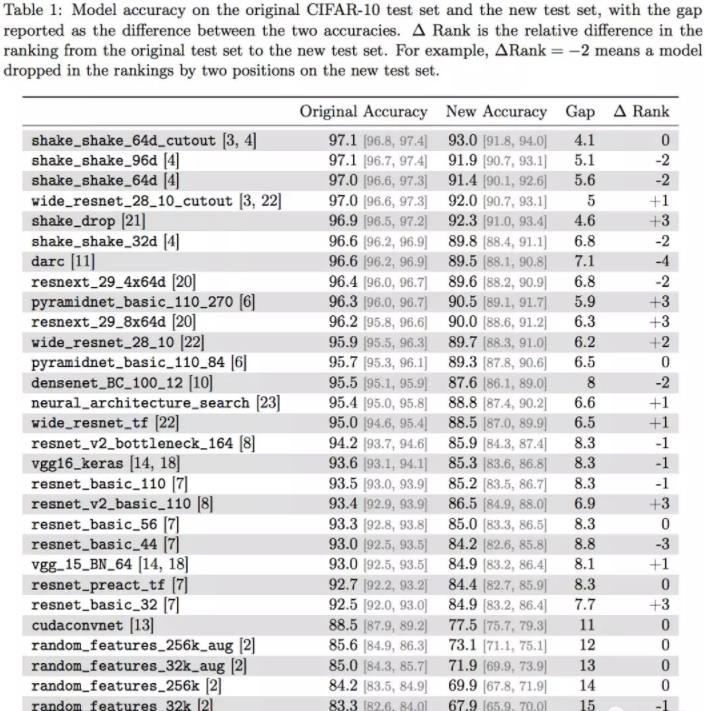
著名的VGG和ResNet,分类准确率从93%左右下降到了85%左右,8个百分点凭空消失。
各位作者还在准确率的差异上,发现了一个小趋势。在原版CIFAR-10上准确率比较高的那些新模型,在新测试集上的成绩下滑不那么明显。
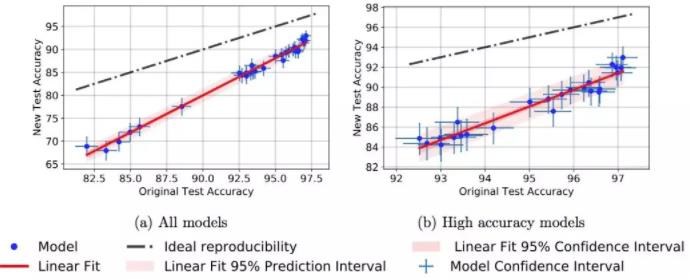
Figure 2: Model accuracy on new test set vs. model accuracy on original test set.
比如说成绩最好的Shake Shake模型,在新旧测试集上的准确率只差4个百分点。
论文中说,这个小趋势说明换个数据集成绩就下降可能不是因为基于适应性的过拟合,而是因为新旧测试集之间,数据的分布上有一些小变化。
但终究,那些为CIFAR-10打造的分类器,泛化性能依然堪忧。
质疑引热议
这个研究如同一枚深水炸弹。
Filip PieKniewski 说:
This is a great studu! I’m calling this problem “meta-overfitting”, and ML has been brushing it under the carpet for years now. The models learn datasets and datasets only, not the reality that generated thoes datasets.
前不久曾撰文唱衰人工智能的的Filip Piekniewski,称赞这篇论文是一个伟大的研究。他还把这个问题,称为“元过拟合”(meta-overfitting)。他还批评机器学习这几年只关注几个数据集,不关注现实情况。
俄勒冈州立大学教授Thomas G. Dietterich指出,不仅仅是CIFAR10,所有的测试数据集都被研究者们很快搞得过拟合了。测试基准需要不断有新的数据集注入。
“我在MNIST上也见过类似的情况。一个准确率达到99%的分类器,换一个全新的手写数据集,立刻掉到90%。”OpenAI的研究员Yaroslav Bulatov说。
Stating the obvious: a lot of current deep learning sticks are overfit to the valiaation sets of well-konwn benchmarks, including CIFAR10. It’s nice to see this quantified. This has been a problem with ImageNet since at lease 2015. arxiv.org/abs/1806.00451
Keras作者Fran?ois Chollet显得更为激动。他说:“显而易见的是,一大票目前的深度学习tricks都对知名的基准测试集过拟合了,包括CIFAR10。至少从2015年以来,ImageNet也存在这个问题。”
如果你的论文,需要固定的验证集,以及特定的方法、架构和超参数。那么这个就不是验证集,而是训练集。这种特定的方法,也不一定能泛化到真实数据上。
深度学习的研究,很多时候使用了并不科学的方法。验证集过拟合是一个值得注意的地方。其他问题还包括:基准太弱、实证结果不支持论文想法、大多数论文存在可重复性问题、结果后选等。
比方你参加Kaggle竞赛时,如果只根据验证集(public leaderboard)数据来调整你的模型,那么你在测试集(private leaderboard)只会一直表现不佳。这在更广泛的研究领域也是如此。
最后给一个非常简单的建议,可以克服这些问题:使用高熵验证过程,例如k-fold验证,或者更进一步,使用带shuffling的递归k-fold验证。只在最后用官方验证集上检查结果。
“当然,这样做成本更高。但成本本身就是一个正则因子:它迫使你谨慎行动,而不是把一大坨面条扔到墙上,看最后哪根能粘住。”Fran?ois Chollet说。
不止图像分类
其实,这个过拟合的问题并不是只出现在图像分类研究上,其他模型同样无法幸免。
今年年初,微软亚洲研究院和阿里巴巴的NLP团队,在机器阅读理解数据集SQuAD上的成绩超越了人类。
当时,SQuAD阅读理解水平测试的主办方,斯坦福NLP小组就对自己的数据集产生了怀疑。
他们转发的一条Twitter说:
How about testing these models on more complex datasets? I have the feeling SQuAD is a really exhausted resource and requires very limited “understanding”. It feels like the community is totally overfitting on this dataset.
好像整个研究界都在这个数据集上过拟合了。
Google Brain研究员David Ha也说,很期待在文本和翻译领域也有类似的研究,他说如果在PTB上也看到类似的结果,那可真是一个好消息,也许更好的泛化方法会被发现。
论文
这篇论文的作者,包括来自UC Berkeley的Benjamin Recht、Rebecca Roelofs、Vaishaal Shankar,以及来自MIT的Ludwig Schmidt。
论文传送门:Do CIFAR-10 Classifiers Generalize to CIFAR-10? https://arxiv.org/abs/1806.00451
198 thoughts on “机器学习5年大跃进,可能是个错觉”